Beyond Sequential: Scaling Existing Medical Pipelines with ‘futurize’
- Easy!
University of California, San Francisco
R Foundation, R Consortium
@HenrikBengtsson
![]()
![]()
Medical research is powered by trusted R packages
boot |
Bootstrap resampling for robust confidence intervals |
lme4 |
Mixed-effects models for longitudinal patient data |
survival |
Time-to-event analysis for clinical endpoints |
DESeq2 |
Differential expression in RNA-seq data |
scater |
Single-cell RNA-seq analysis, e.g. PCA, t-SNE, UMAP |
| … | … |
Packages are distributed via the highly-trusted CRAN and Bioconductor repositories:
With supporting repositories such as R-universe, Pharmaverse, and R-multiverse:
Growing datasets make sequential analysis a bottleneck
- Bootstrapping confidence intervals - 1,000 replicates × large cohort = hours
- Mixed models across patient subgroups - dozens of subgroup fits, one after another
- Simulation studies for sample-size planning - 10,000 iterations on a laptop overnight

← 32× CPU cores sitting idle
Parallelization can help →
Barrier is friction!
The R community has embraced the Futureverse
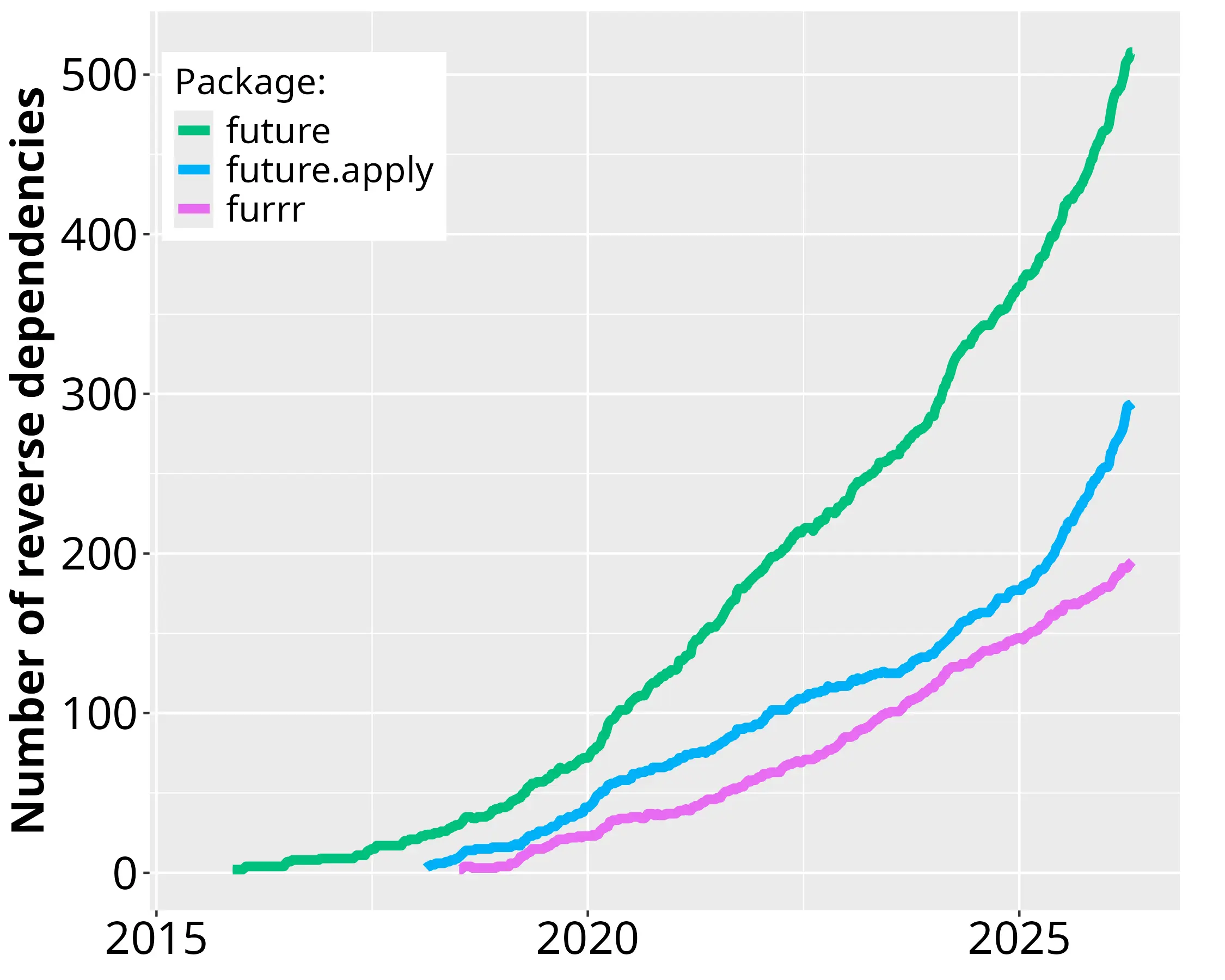
+30% reverse dependencies yearly
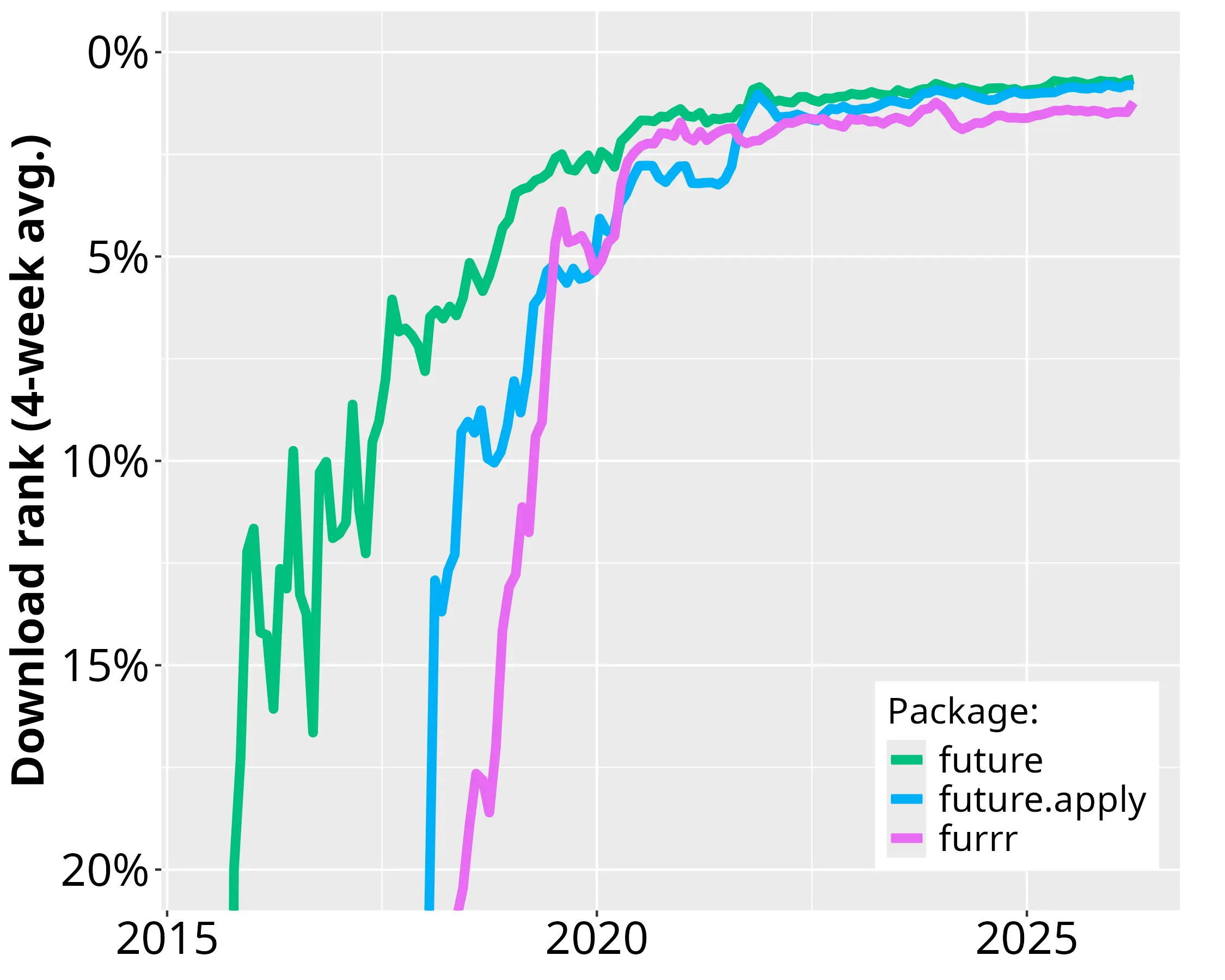
Top 0.7% most downloaded
… but, we can simplify it further with ‘futurize’
All you need to remember is futurize()
New package futurize preserves your original code
![]()
- Universal adapter: One unifying function
futurize() - Zero rewrites: Original logic unchanged
res <- lapply(patients, fit_model) |>
futurize()library(purrr)
res <- map(patients, fit_model) |>
futurize()library(foreach)
res <- foreach(p = patients) %do% {
fit_model(p)
} |> futurize()library(plyr)
res <- llply(patients, fit_model) |>
futurize()library(BiocParallel)
res <- bplapply(patients, fit_model) |>
futurize()library(crossmap)
res <- xmap(x, ~ .y * .x) |>
futurize()Easy!
… we can do even more with ‘futurize’
All you need to remember is futurize()
Bootstrap simulations accelerated with futurize()
Sequential:
library(boot)
b <- boot(data = cohort, statistic = cox_stat, R = 100e3)100,000 bootstrap replicates takes hours on large cohorts!
A single worker
Parallel:
plan(future.mirai::mirai_multisession)
library(boot)
b <- boot(data = cohort, statistic = cox_stat, R = 100e3) |>
futurize()Faster when distributed across parallel workers.
Identical results.
32 parallel workers
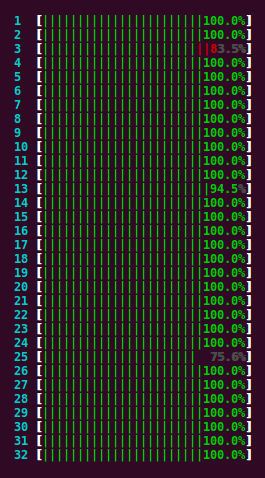
Yes, we can do progress reporting too
All you need to remember is progressify()
Go compute and may the future be with you!
Easy to install:
install.packages(c("futurize", "progressify"))Easy to use:
ys <- lapply(xs, fcn) |> progressify() |> futurize()Stay with your favorite coding style:
ys <- xs |> map(fcn) |> progressify() |> futurize()Available elsewhere too:
ys <- glmnet::cv.glmnet(x, y) |> futurize()![]()
![]()
![]()